| Character Set, Character Encoding ve Character Reference Nedir | |||||
a. Character Sets Nedir? Karakterlere karşılık teorik, soyut sayılar eşleşmesinin yapıldığı karakterler kümesine character set (charset) adı verilir. Örneğin "Unicode (Universal Character Set)" karakterlerin benzersiz decimal sayılarla ifade edildiği karakterler setine denir. Mesela A = 65, B = 66, C = 67 ,... olarak karakter setinde yer alır. Bu şekilde örneğin “hello” string'i Unicode karakter setinde 104 101 108 108 111 h e l l o ile karşılık görür. Unicode tüm dünyada kullanılmakta olan hemen hemen her bir harfi içeren karakter setine bir örnektir. ASCII, internet tarihindeki ilk karakter seti standardıdır. Bu karakter seti tam olarak 128 farklı alphanumeric karakter tanımlar: Numbers (0-9), English Letters (A-Z) ve special Characters (örn; !$+-()@<>). ANSI (Windows-1252) Windows tarihindeki ilk karakter setidir. Tam olarak 256 farklı karakter tanımlar. ISO-8859-1 (Latin-1) HTML 4 için ilk default karakter setidir. İngiliz alfabesi dışında "i", "ü", "ç",... gibi karakterleri de içerir. Tam olarak 256 farklı karakter tanımlar. b. Character Encodings Karakter setlerindeki harflerin karşılık geldiği teorik, soyut sayıların binary olarak nasıl tutulacağı yönündeki tekniğe / yönteme character encoding adı verilir. Character Encoding karakterleri benzersiz binary sayılarla ifade eder. Örneğin UTF-8, UTF-16, UTF-32, ... birer character encoding'tirler. c. "Character Sets" vs. "Character Encodings" İnternetteki ilk karakter seti olan ASCII karakter seti icat edildiğinde ve sonrasında charset ve character encoding arasında bir fark bulunmamaktaydı. İki kavram da aynı şeyi ifade ediyordu. Her ikisi de karakterlerin nasıl binary olarak tutulacağını ifade ediyordu. Fakat Unicode charset’i icad edildikten sonra arada bir fark oluştu. Unicode charset’inin icadı ile karakterlerin binary halde tutulması 2 adımdan oluşur hale geldi. Bu adımlar;
şeklindendir. Örnek vermek gerekirse € karakteri karakter setlerinde bir teorik, soyut sayı karşılığına (code point sayısına) sahiptir ve bu teorik, soyut sayı da farklı encoding yöntemleri ile farklı farklı binary’ler halinde somut olarak tutulmaktadır. 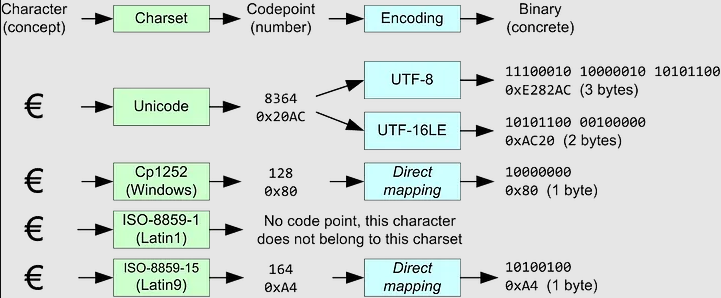
Yani € karakteri Unicode karakter setinde varmış ve UTF-8 ile encode’landığında farklı, UTF-16LE ile encode’landığında farklı binary’ler halinde tutulmaktaymış veya € karakteri ISO-8859-1 karakter setinde yer almamaktaymış ve bu nedenle bu karakter setinde herhangi bir teorik, soyut sayı karşılığına sahip değilmiş. Sonuç olarak karakter setleri (charset’ler) karakterlerin bilgisayarda hangi teorik / soyut sayısal değerlerle depolanacağını belirler. Character Encoding'ler ise karakterlerin bilgisayarda hangi binary değerlerle depolanacağını belirler. Dolayısıyla ASCII bir karakter setidir ve karakterlerin hangi decimal değerlerle bilgisayarda depolanacağını tanımlar. UTF-8 ise bir character encoding’tir ve karakterlerin hangi binary değerlerle bilgisayarda depolanacağını tanımlar. Character Set ve Encodings Üzerine Charset ve character encoding kavramları önceleri aynı, sonradan farklı anlamlar ifade eder olduklarından dolayı günümüzde internet dili html tasarlanırken tasarımda eski ifade kalmıştır ve günümüze kadar gelmiştir.
// HTML 4'de charset belirleme
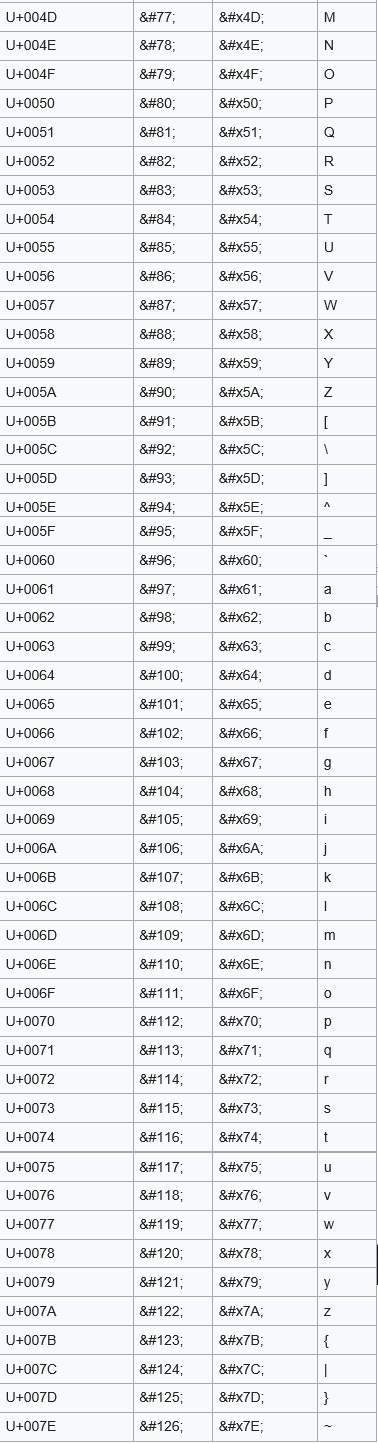
<meta http-equiv="Content-Type" content="text/html; charset="utf-8"> // HTML5'de charset belirleme <meta charset="UTF-8"> // Includekarabuk 'deki <meta etiketi <meta http-equiv="Content-Type" content="text/html; charset="utf-8"> Bu html ifadelerdeki utf-8 bir charset değildir. Bir character encoding’tir. Fakat html sayfalarda character encoding’i belirtirken charset keyword’ü halen kullanılmaktadır. Character Encoding ve Encryption Üzerine Encoding, karakterlerin binary olarak 0 ve 1’ler ile nasıl depolanacağını belirler. Encoding = characters -> binary Encryption, karakterlerin binary olarak 0 ve 1’ler ile depolanması sonrası bu 0 ve 1’lerin nasıl başka 0 ve 1’lere dönüştürüleceğini belirler. Encryption = understandable binary -> unintelligible binary ( anlaşılır binary ) ( anlaşılmaz binary ) Encoding ile oluşan kaynak 0 ve 1’ler başkalarınca anlaşılabilir. Dışarıdan bu 0 ve 1’lerin korunması ve anlaşılamaması amacıyla encryption kullanılır. Not: Encryption framework’ler bazen hem encoding hem encryption arka arkaya uygulayabilmektedirler. Bu ise bu iki kavramın birbirine karışmasına neden olabilmektedir. Fakat bu iki kavram ayrı iş yapmaktadırlar. d. Character Reference Karakter referansı Unicode karakter setlerindeki karakterleri referans yoluyla çağırmamızı sağlayan kodlamalardır. HTML'deki numerik “karakter referans”ları Unicode (Universal Character Set) 'daki karşılık gelen bir karakteri gösterirler. Numerik karakter referanslarının formatı şu şekildedir: &#nnnn; ya da &#xhhhh; nnnn olan format decimal form'dur. hhhh olan ise hexadecimal form'dur. nnnn ve hhhh herhangi bir sayı alabilir. Karakter referansı mevcut karakter setinde tanımlı karakterleri örneğin html dökümanına referans yoluyla dahil edebilmemizi sağlar. Mesela Türkçe klavye kullanan bir kimse klavyesinden matematiksel sembolleri normal şartlarda çıkaramaz. Çünkü karakter setinde tanımlı o matematiksel sembolleri klavyeden çıkarmak uzun ve karmaşık tuş kombinasyonları gerektirir. Bu komplike yöntem yerine ilgili karakterin karakter referansı kullanılabilir ve istenilen semboller böylece ekrana verilebilir. Aşağıda bir html dökümanına klavyeden girilebilmesi mümkün olan karakterlerin “karakter referansları” verilmiştir: 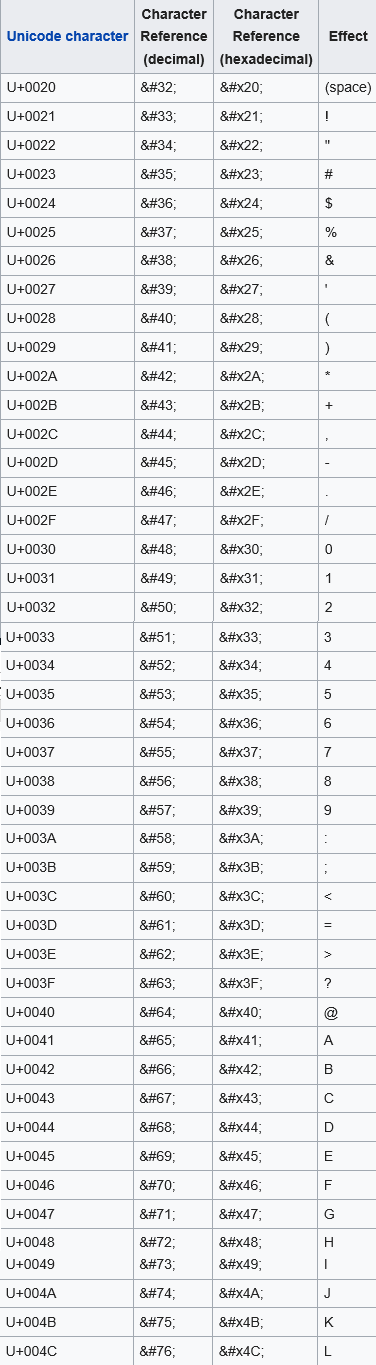
Örneğin A karakteri ASCII karakter setinde 65 decimal sayısıyla ifade edilmekteydi. Bu karakter setindeki A karakterini referans yoluyla çağırmak için 
A decimal referansı ya da A hexadecimal referansı kullanılabilir.
/var/www/characterReferenceSample2.html
A ve A Çıktı: 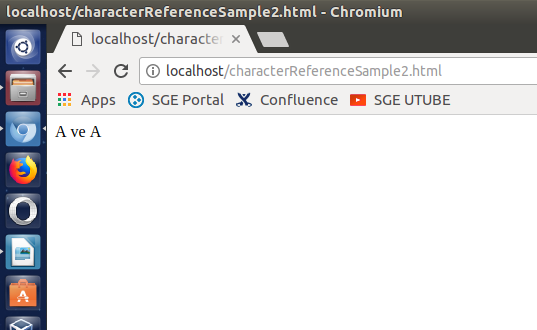
Böylece karakter referansları ile biz karakter setinde tanımlı karakterleri html dökümanına ekleyebiliriz. Aşağıda ise karakter setinde yer alsa bile normal şartlarda klavyeden çıkarılamayacak bir matematiksel sembolün karakter referansı gösterilmiştir: 
Karakter setindeki Σ sembolünü referans yoluyla çağırmak için Σ decimal referansı ya da Σ hexadecimal referansı kullanılabilir.
/var/www/characterReferenceSample.html
Σ ve Σ Çıktı: 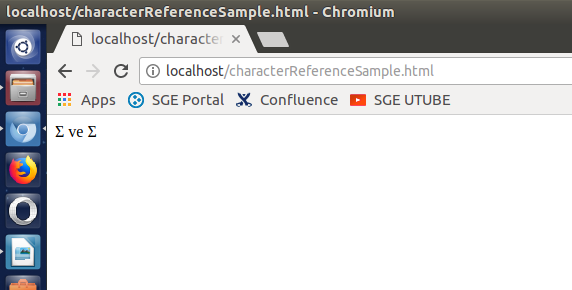
Character Reference'ı yanında bir de Character Entity Reference'ı vardır. Character Reference'ları decimal ya da hexadecimal sayıları kullanarak karakter setindeki bir karakteri göstermeye yararken “Character Entity Reference”ları ise isim kullanarak karakter setindeki bir karakteri göstermeye yarar. Örneğin HTML'de öntanımlı entity'ler (> , " , & , … v.b.) ilgili karakterleri gösterirken DTD'de öntanımlı entity'ler ve ayrıca explicitly olarak kendi tanımladığımız entity'ler ilgili karakterleri gösterir. Character entity referanslarının formatı şu şekildedir.
&name;
Yararlanılan Kaynaklar
|
|||||
 Bu yazı 19.08.2024 tarihinde, saat 13:34:27'de yazılmıştır.
19.08.2024 tarihi ve 14:03:56 saatinde ise güncellenmiştir.
Bu yazı 19.08.2024 tarihinde, saat 13:34:27'de yazılmıştır.
19.08.2024 tarihi ve 14:03:56 saatinde ise güncellenmiştir. |
|||||
|
|||||
| Yorumlar |
|||||
| Henüz yorum girilmemiştir. | |||||
| Yorum Ekle | |||||

|
|
|||
| -> | Genel | ||
| -> | Webgoat Uygulaması | ||
| -> | DVWA Uygulaması | ||
| -> | Çeşitli Sızma Teknikleri | ||
| -> | Güvenlik Araçları | ||
| -> | Linux Temelleri | ||
| -> | Genel Kültür (Siber Güvenlik) | ||
|
|
|||
|
|